产品介绍
Meta 的 Omnilingual ASR 是一个开源(Apache 2.0 许可证)语音识别模型,支持 1,600+ 种语言。它采用基于 LLM 的架构,可以仅通过几个上下文示例扩展到新语言,无需重新训练。
适合谁关注
- 开发者和技术团队
- 设计师、内容创作者和视觉团队
- 教育产品团队和学习工具用户
- 正在评估 AI 工具或智能体落地的团队
可借鉴场景
- 快速理解 Omnilingual ASR 的定位、核心能力和 Product Hunt 热度
- 判断“推进 1,600+ 语言的自动语音识别”这类需求是否值得做竞品调研
- 沿着 开发者工具、AI 与智能体 继续发现同类产品和替代方案
- 筛选高票产品,观察海外用户当前愿意投票支持的产品形态
132
投票数
3
评论数
11月11日
发布日期
作者自荐
总结
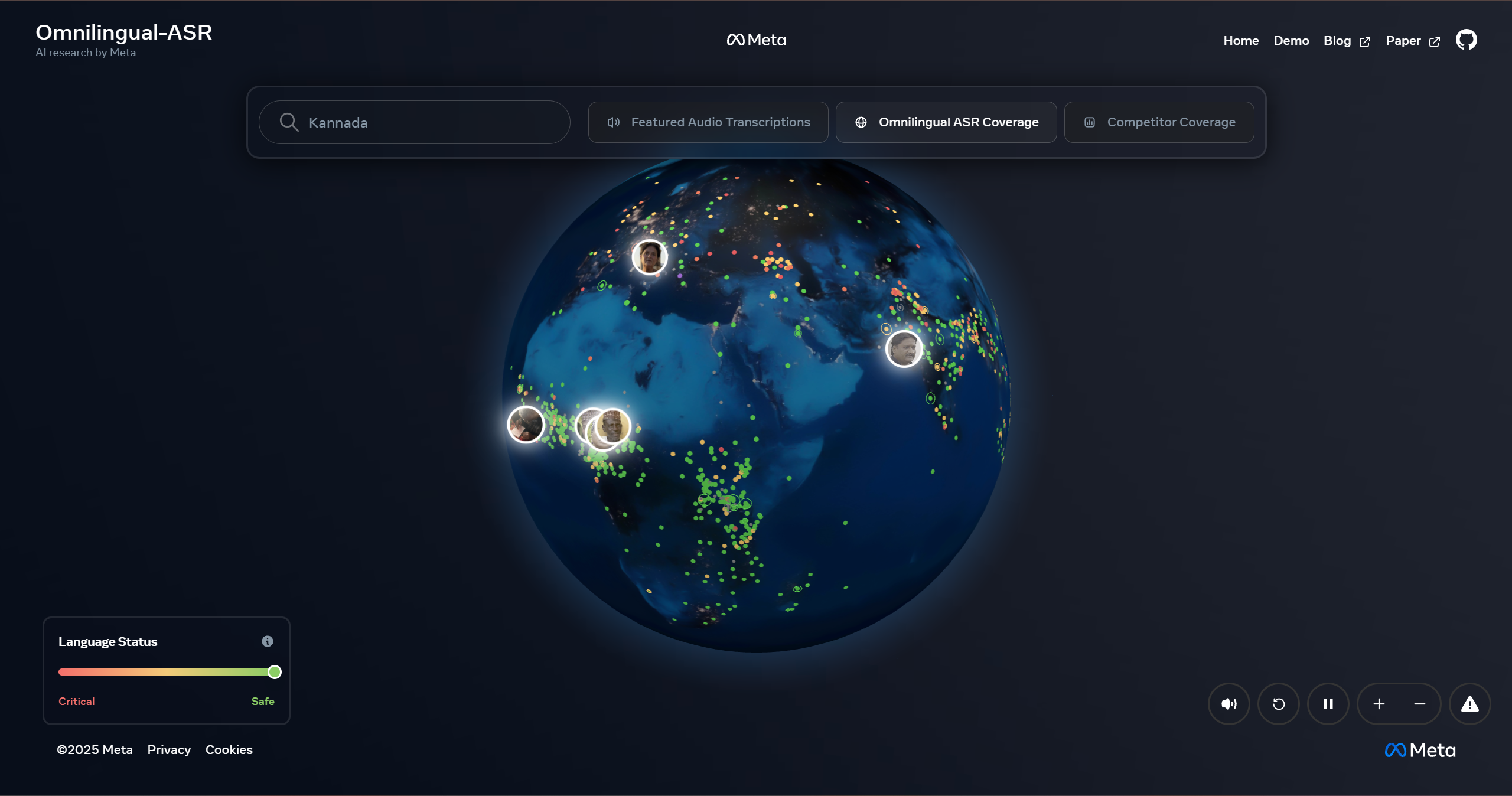
Omnilingual ASR 解决了语音识别领域长期存在的"语言不平等"问题。在全球 7,000+ 种语言中,超过 1,500 种处于低资源状态,传统 ASR 系统对这些语言的支持极为有限。Meta 此次开源的模型突破性地支持 1,600+ 语言,这对全球语音应用生态具有深远影响。其创新之处在于采用 LLM 架构,使得新语言扩展无需重新训练,降低了门槛。开发者可将其作为主模型的补充,快速覆盖小众市场。目标用户包括多语言语音应用开发者、国际化平台和语言保护倡议。挑战在于模型的实际性能在极低资源语言上的表现,以及推理延迟在实际应用中的可用性。
GitMemo免费开源
把 AI 对话保存到你的 Git 知识库
本地优先,支持 macOS 与 Android。剪贴板、截图、笔记和文件都能集中保存、搜索、同步。
获取安装包
大家好! Meta FAIR 刚刚开源了一个支持 1,600 种语言的 ASR 模型。(没错,就是 1,600 种。) 它以 Apache 2.0 许可证发布,涵盖了几乎所有能想到的低资源语言。无论开发什么语音应用,这都可以作为主 ASR 模型的强大补充,让应用覆盖更广泛的用户群体。 语言连接世界,但许多小众语言正在消失。Meta 还将数据集转化为一个交互式语言探索地图,用户可以在线聆听这些语言。这是体验世界语言多样性的绝佳方式。