
产品介绍
一套基于先进理论的量化算法,能够为大语言模型和向量搜索引擎实现大规模压缩。
适合谁关注
- 教育产品团队和学习工具用户
- 正在评估 AI 工具或智能体落地的团队
可借鉴场景
- 快速理解 TurboQuant 的定位、核心能力和 Product Hunt 热度
- 判断“谷歌推出的新型LLM压缩算法”这类需求是否值得做竞品调研
- 沿着 硬件、移动与平台、AI 与智能体 继续发现同类产品和替代方案
- 筛选高票产品,观察海外用户当前愿意投票支持的产品形态
226
投票数
2
评论数
3月25日
发布日期
作者自荐
总结
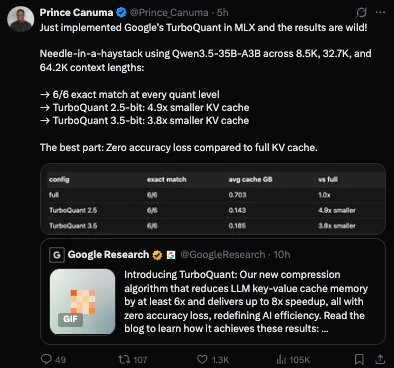
TurboQuant 直击当前 AI 规模化部署的核心痛点——内存瓶颈。随着模型参数量的爆炸式增长,硬件成本与性能限制已成为阻碍 AI 应用普及的关键因素。该算法通过创新的 PolarQuant 和 QJL 技术,在近乎无损的前提下实现高达 3 比特的超低位压缩,将 KV 缓存内存减少 6 倍以上,这不仅是效率的提升,更是部署范式的变革。其最大价值在于无需重新训练或微调,即可让现有模型在资源受限的边缘设备(如仅 16GB RAM)上运行,极大地拓宽了 AI 的应用场景。目标用户包括所有需要部署大型语言模型或向量搜索引擎的云服务商、硬件制造商和应用开发者。潜在挑战在于算法在不同模型架构和任务上的泛化能力,以及压缩后模型在极端推理场景下的稳定性。这标志着 AI 从追求绝对性能向追求性能-效率平衡的重要转变。
GitMemo免费开源
把 AI 对话保存到你的 Git 知识库
本地优先,支持 macOS 与 Android。剪贴板、截图、笔记和文件都能集中保存、搜索、同步。
获取安装包
谷歌最近势头正猛,大家认为有了TurboQuant,我们是否能在仅16GB内存的设备上运行强大的LLM模型了? TurboQuant是什么? TurboQuant将AI最大的隐藏瓶颈之一——内存,转变为一个已解决的问题。这可能是大规模AI系统最重要的效率突破之一? 它通过大规模压缩驱动LLM和搜索引擎的向量,同时不牺牲精度,从而弥合了模型性能与系统限制之间的差距。 TurboQuant的工作原理是重新思考数据的存储和比较方式。它不再保留庞大高精度的向量,而是将其压缩成超紧凑的表示形式,同时保留其含义和关系。这使得AI系统能够运行得更快、成本更低,并实现更大规模部署。 它结合了两种新颖的技术。PolarQuant将向量数据重构为更易压缩的几何形式,而QJL则使用微小的1位校正层来消除误差。两者结合,实现了近乎无损的压缩,且开销几乎为零。 一次压缩,全面提升。内存使用量下降,检索速度加快,长上下文性能也变得更加高效。 核心能力: - 超低位压缩,低至约3比特 - 精度损失近乎为零 - KV缓存内存减少6倍或更多 - 注意力机制和向量搜索速度提升高达8倍 - 无需重新训练或微调 在AI正触及硬件和扩展极限的当下,TurboQuant感觉像是一个根本性的解锁方案,能让模型变得更小、更快,并能在任何地方部署。 大家认为这将如何改变游戏规则?