
产品介绍
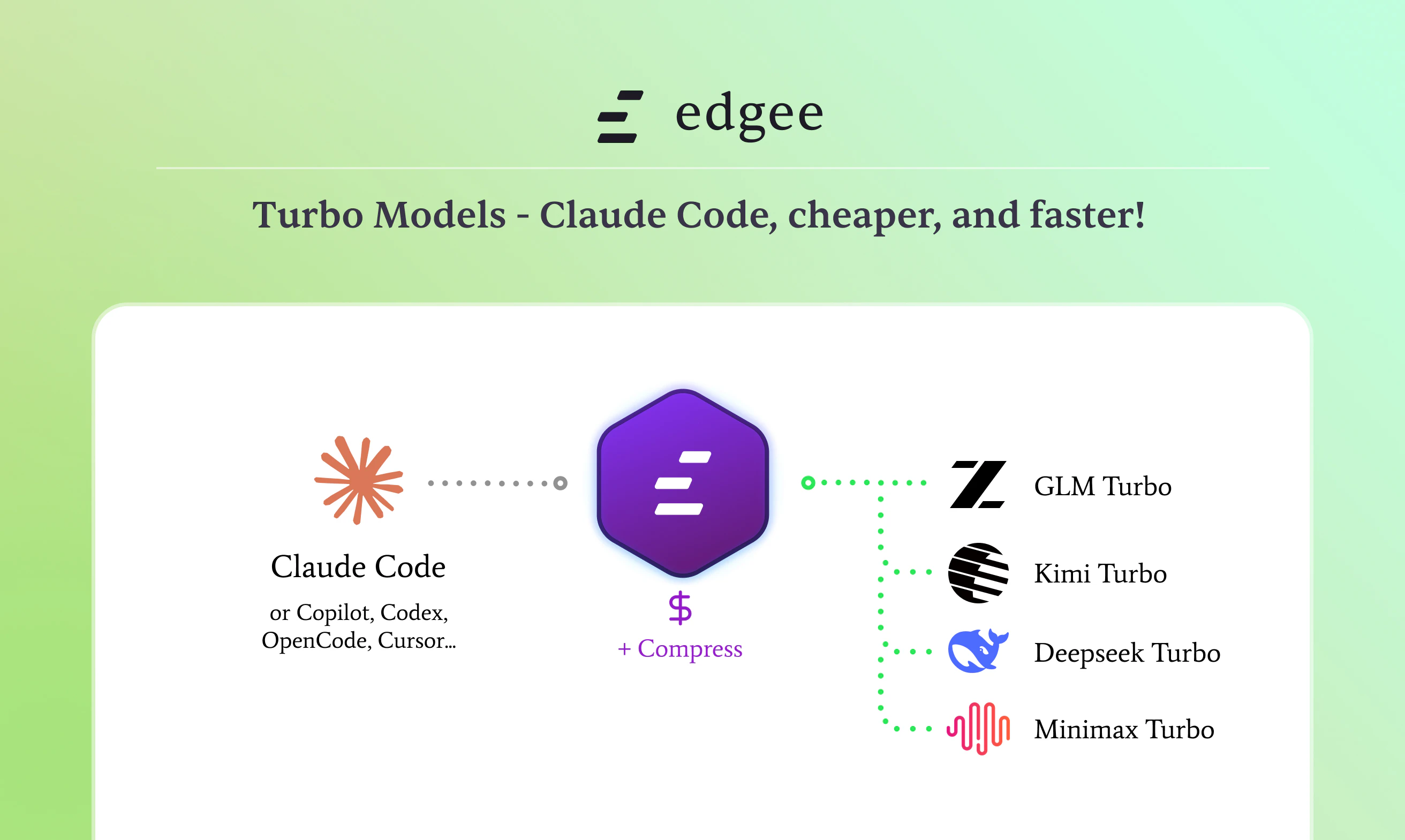
在 Claude Code 中运行最先进的开源模型(GLM 5.1、Kimi K2.7 Code、MiniMax M2.7 等),速度最高可提升 4 倍(最高 200 tok/s),每月固定 29 美元。几分钟即可完成配置,无需修改代码。
适合谁关注
- 开发者和技术团队
- 正在评估 AI 工具或智能体落地的团队
可借鉴场景
- 快速理解 Edgee Turbo Models 的定位、核心能力和 Product Hunt 热度
- 判断“在 Claude Code 中使用 Kimi K2.7 Code、MiniMax M2.7 等开源模型”这类需求是否值得做竞品调研
- 沿着 开发者工具、AI 与智能体 继续发现同类产品和替代方案
- 筛选高票产品,观察海外用户当前愿意投票支持的产品形态
- 结合评论热度,判断该产品是否有真实讨论和早期用户反馈
163
投票数
28
评论数
6月16日
发布日期
作者自荐
总结
Edgee Turbo Models 精准切入了 AI 编码工具链中一个被忽视但至关重要的瓶颈——推理速度。当开源模型在编码质量上逐渐追平闭源模型时,缓慢的推理速度和繁琐的配置流程成为实际落地的最大障碍。Edgee 通过专用高吞吐量推理基础设施将速度提升至 4 倍,同时保持完整模型权重不做量化妥协,这一技术路线既务实又有说服力。每月 29 美元的固定定价策略在 agent 密集调用场景下极具成本优势,直接消除了按量计费带来的不确定性。结合其已有的压缩、回退、团队观测等功能,Edgee 正在构建一个完整的 Agent Gateway 技术栈。主要挑战在于开源模型的迭代速度极快,需要持续跟进新模型支持,同时固定定价模式下的成本控制能力将决定商业可持续性。
GitMemo免费开源
把 AI 对话保存到你的 Git 知识库
本地优先,支持 macOS 与 Android。剪贴板、截图、笔记和文件都能集中保存、搜索、同步。
获取安装包
大家好,Product Hunt 👋 我是 Sacha,Edgee 的联合创始人。 分享一个故事。几周前我在用 Claude Code 配合 Opus 做一次重构。模型完全知道该怎么做,但我只能坐在那里看着一个 500 行的文件一个 token 一个 token 地慢慢输出。一个文件就要两分钟。把这个时间乘以 agent 循环中的每一步,就会意识到:速度是每次编码过程中的隐性成本。 差不多同一时期,我开始测试 GLM 和 Kimi K2.7 等开源模型。在编码任务上的质量确实令人印象深刻。 但标准端点上的速度甚至比闭源模型还慢。而且配置过程很痛苦:API 密钥、代码修改、CLAUDE md 文件重写、MCP 服务器重新配置。 这就是我们构建 Edgee Turbo Models 要解决的问题。 功能概览: → 在 Claude Code 中直接运行前沿开源模型(GLM 5.1、Kimi K2.7 Code、Kimi K2.6、MiniMax 2.7)。 → 速度最高可达标准端点的 4 倍(约 200 tok/s vs 约 50 tok/s)。 → 每月固定 29 美元。不会因 agent 工作量增加而产生不断攀升的按量计费账单。 → 2 分钟完成配置。CLAUDE md、MCP 服务器和整个环境配置保持不变。 有一点需要提前说明,因为一定会有人问: Turbo 不是这些模型的缩小版或量化版。它们是完整的开放权重检查点。Turbo 只改变了服务方式——运行在专为高吞吐量推理打造的专用基础设施上,而非共享的尽力而为端点。输出完全相同,只是更快。 与之前发布产品的关系: - 压缩:减少每次请求的 token 用量 - 团队:按仓库、按 PR 查看使用情况 - 回退模型:当 Claude 或 Copilot 达到限制时保持工作不中断 - Turbo 模型:以固定价格高速运行开源模型 这些组合在一起就是 Agent Gateway 的路由 + 压缩 + 观测技术栈。今天发布的是速度层。 为什么是现在:《经济学人》本周发表了一篇文章,确认"token 最大化时代已经结束",企业正在将请求路由到更便宜的模型。开源模型显然是答案的一部分。Turbo 让它们真正可用。 希望得到一些反馈: → 最想尝试哪个开源编码模型? → 每月固定 29 美元的定价是否合适,还是更倾向按量计费? → Turbo 系列还应该加入哪些模型? 我会全天在评论区。感谢关注 🙏