
产品介绍
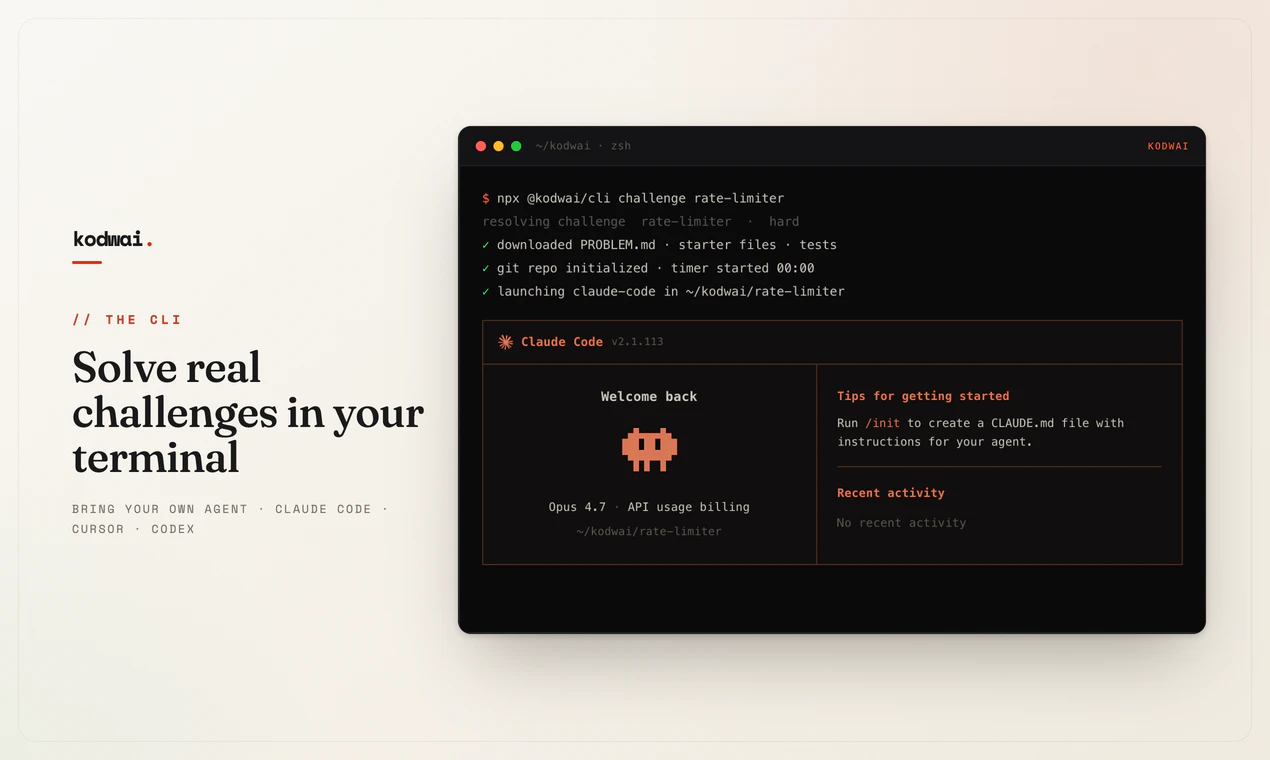
Kodwai 是首个评估与 AI 编程 agent(Claude Code、Cursor、Codex)协作能力的平台。在本地终端中完成真实挑战,CLI 工具会捕获代码、测试、Git 历史、agent 对话记录和用时,然后从三个维度进行评分:引导力、成果和提升力,每项评分都附有对应的证据。通过公开排行榜展示排名,获取徽章,打造能展示真实工程能力而非死记硬背水平的个人档案。免费使用,自带 agent 即可。
适合谁关注
- 开发者和技术团队
- 教育产品团队和学习工具用户
- 正在评估 AI 工具或智能体落地的团队
可借鉴场景
- 快速理解 kodwai 的定位、核心能力和 Product Hunt 热度
- 判断“首个为 Vibe Coding 能力评分的平台”这类需求是否值得做竞品调研
- 沿着 教育与学习、开发者工具 继续发现同类产品和替代方案
22
投票数
8
评论数
6月28日
发布日期
作者自荐
总结
Kodwai 精准捕捉到了 AI 编程时代的核心变化:开发者的核心竞争力正在从"写代码"转向"驾驭 AI agent 写代码"。传统的 LeetCode 和笔试作业已无法衡量这种新技能,而 Kodwai 提出了"引导力、成果、提升力"三维评估框架,并将引导力权重设为最高,体现了对 AI 协作本质的深刻理解。产品定位巧妙——既是开发者的技能展示平台,也是企业的面试工具,具备双边市场潜力。免费加自带 agent 的策略降低了使用门槛。主要挑战在于如何建立评分体系的行业公信力,以及如何在 Vibe Coding 概念尚未完全主流化的阶段获取足够的用户基数来激活排行榜的网络效应。
GitMemo免费开源
把 AI 对话保存到你的 Git 知识库
本地优先,支持 macOS 与 Android。剪贴板、截图、笔记和文件都能集中保存、搜索、同步。
获取安装包
大家好,Product Hunt!我是 Hakan,Kodwai 的创始人。 三年前,每一行代码都靠手打。如今大多数人通过指挥 agent 来编程——引导它、纠正它、在它自信地犯错时及时拦住它。这才是真正的技能,然而目前没有任何工具能衡量它。LeetCode 考的是背诵算法,笔试作业考的是空闲时间,两者都无法反映实际工作方式。 所以我打造了 Kodwai。选择一个真实挑战,在本地机器上用自己的 agent(Claude Code、Cursor 或 Codex)完成,然后提交。系统会从三个维度评分:引导力(如何引导和验证 agent)、成果(交付了什么以及是否通过测试)、提升力(一次性提示词无法覆盖的边界情况)。每项评分都指向其背后的证据。 引导力的权重刻意设为一半。一个草率的提示词即使通过了测试,得分仍然会很低,因为有效引导 agent 始终是最难的部分。 对开发者免费,提供公开排行榜和个人档案,可以用来替代笔试作业。团队可以在同一引擎上进行面试,查看真实的操作过程。 与 agent 结对编程时,怎么判断进展顺利还是出了问题?这正是我想要衡量的,欢迎随时交流。kodwai.com